Clojureの作者が作ったデータベースDatomicが凄い
![]() プログラミング言語Clojureの作者Rich Hickey氏率いるClojure HackerのチームがDatomic(デートミックと発音するらしい)というデータベースをリリースしました。これが何やらとてつもないです。10年先を行ってる技術じゃないでしょうか。
まだ本番サービスは始まっていませんが開発環境用のライブラリが配布されています。
Datomicは斬新なアーキテクチャなので一言で説明するのはとても難しいです。
私が理解できたことを簡単に説明します。
プログラミング言語Clojureの作者Rich Hickey氏率いるClojure HackerのチームがDatomic(デートミックと発音するらしい)というデータベースをリリースしました。これが何やらとてつもないです。10年先を行ってる技術じゃないでしょうか。
まだ本番サービスは始まっていませんが開発環境用のライブラリが配布されています。
Datomicは斬新なアーキテクチャなので一言で説明するのはとても難しいです。
私が理解できたことを簡単に説明します。
2014/1/20追記
ライセンスモデル、サポートストレージ、サービスとしてではなく独立して使用する形になるなど記事作成時の内容から色々変更が合った部分を更新しました。
変更不可なAppend-onlyデータベース
従来のデータベースで、あるレコードを変更するというのはそのレコードに対応した場所があり、そこのデータを書き換えるということを意味していました。
Datomicでは書き換え可能な場所はなく、過去の事実を時刻と共に全て記録します。
例えば、大統領がブッシュからオバマに変わっても、過去にブッシュが大統領だったという事実は消えません。
ある時刻で大統領がブッシュだったという事実とは別に、単にある時刻で大統領がオバマになったという事実が記録されるのです。
現時点で誰が大統領なのかは時刻が新しい方を見れば分かります。
全ての新たな事実の追加(ライト)は後述するTransactorによって完全に順序付けされています。
つまり、任意の時点のデータベースとは、その時点までの事実の単なる集合に過ぎないのです。
過去の任意の時点が完全な状態で記録されているため、任意の時点に対してクエリーを投げることができます。
ここまで聞くと同じように append-only なデータベースReThinkDBなどを思い浮かべるかもしれません。
Datomicは変更不可性の強みを更にレバレッジするユニークな特徴を持っています。
アプリケーションに埋め込まれたクエリーエンジン
従来のデータベースを構成要素に分解すると次の図のようになります。
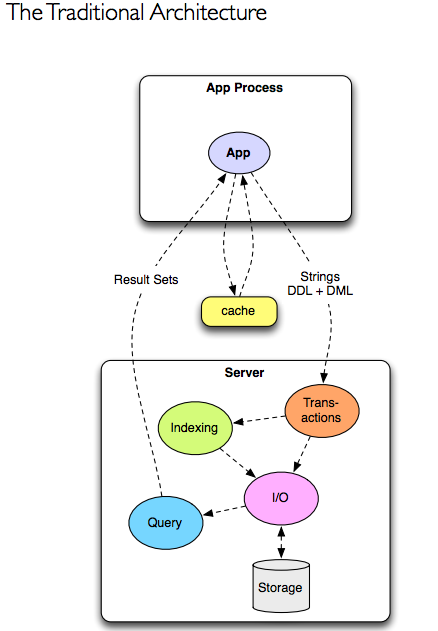
whitepaper(pdf)より
ほとんど全ての処理がDBサーバ側に集中しているのが分かると思います。
アプリケーション側はクエリーを投げて、DBサーバが結果を返してくれるのをただ待ちます。
クエリーのリクエストが多くなるとDBサーバの負荷が高くなり遅くなってしまうので、よくMemcachedなどでDBサーバから返された結果を一時的にキャッシュしたりします。
キャッシュはDBのデータが更新された際にキャッシュ上の古いデータを消すか更新するかしないと、古い値を間違って参照してしまうという問題があります。
Datomicは事実の変更不可性を活かして抜本的にアーキテクチャを再デザインしました。
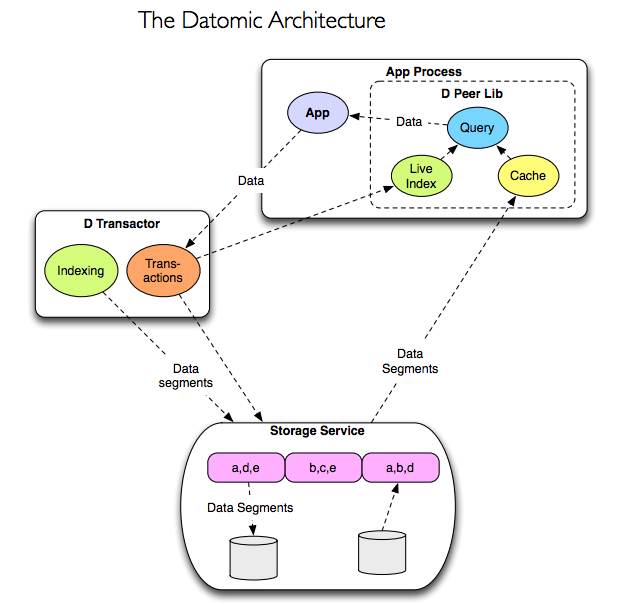
whitepaper(pdf)より
なんとクエリーの処理をアプリケーションに埋め込まれた Datomic Peer Library(図の上側) で行うのです。
これがDatomicの最大の特徴と言えると思います。
アプリケーション側はDBサーバにリクエストを投げるのでなく自分自身でクエリー処理を行っており、もはやただのクライアントではありません。なのでDatomicではアプリケーション側をPeerと呼んでいます。
Peerでクエリーを処理する際に必要なだけのデータをStorage Service(図の下側)から取り寄せ、Peerのローカルにキャッシュします。
あくまでPeerがローカルで保持しているのは変更不可(リードオンリー)のただのキャッシュであり、LRUポリシーで消えていきます。
PeerはTransactor(図の左側)というノードに常時接続しており、新たな事実の追加はTransactorから通知されるため、キャッシュが古い物かどうかを心配する必要はありません。
よってメモリの容量が許す限り貪欲にキャッシュを保持することができます。
何より嬉しいのはクエリーエンジンがキャッシュ機構を隠蔽してくれているということですね。
一旦必要なデータがPeerにキャッシュされさえすれば、Storage Serviceからのデータの引き出しは全くなし(!)でクエリー処理が行えます。
クエリーエンジンはアプリケーションに埋め込まれていて別プロセスでさえないので、ローカルでのソケット通信すら発生しないでしょう。ゼロコピーです。
RAMへのアクセスコストが250サイクル、ネットワークを介したアクセスコストが240000000サイクルと聞いたことがあるのでリードが激しいアクセスパターンでは劇的に高速になると思います。
更によく考えると、各Peerがそれぞれ分散してクエリーを処理するため、その点でも今までDBサーバに任せっきりにしていたのよりも遥かに高いパフォーマンスになると思います。
分散型インデックス
Peerが必要なデータを取り寄せる? インデックスはどうするの?クエリー対象のデータを全部引っ張ってくるの? ものすごく非効率というかサイズが大きいと無理じゃないか? などの疑問が思い浮かびましたが、どうやらそこら辺は大抵の場合うまくやってくれるようです。
難しいのですが、データはStorage Serviceにインデックスを含んだBツリー的な形式で一定単位でまとめて保存されており、一旦ツリーのルートがPeerにキャッシュされさえすればインデックス中の任意のまだキャッシュされていない部分を一回のネットワークアクセスで読み込むことができるそうです。ローカルに全てがインデックスの形式である必要はないのです。この事からRichは「Datomicはある意味、分散型のインデックスです」とコメントしています。
ユーザ定義可能な強力なトランザクション
新たな事実の追加は全てTransactorを介してトランザクション処理され完全に順序付けされます。
更にトランザクションの中でユーザ定義の処理を走らせることができるみたいです。
Rich の Hacker News コメント参照
これは数字のインクリメントやCASなどをユーザ自身で定義でき、それがアトミックに処理できるということを意味しています。
ライトはボトルネックになり得る
Transactorは単一ノードなのでライトが一定量を超えるとボトルネックになり得ます。Richのコメントによれば、この制限は他の様々な利点とのトレードオフであり、Transactorはクエリー、リード、ロック、Diskへの同期という普通のDBサーバに課せられるような多くの処理をしなくてよい分かなりの負荷に耐えられるはずという考えのようです。それでもTransactorがボトルネックになるほどの非常にライトの負荷が高いシステムはDatomicは対象にしていないとのことです。
ライトの対象が論理的に分かれているなら複数DBに分けるという対応も一応はできると思いますが。
また、Transactorが仮に落ちてもTransactorはライトの処理を行っているだけで、リードはPeerとStorage Serviceが処理するためリードには何の影響もありません。Transactorをホットスタンバイ構成などにすればいいだけでしょう。
SQLより柔軟で強力な演繹的クエリーシステムDatalog
まだよく理解できてないので省略。パターンマッチング、遅延ロード、暗黙的なjoinなど。
また、クエリーをローカルで実行するという特性を利用して、アプリ側の言語で書いた関数をクエリー中にフィルターとして含めることができます。すごい。
事実の Atomic な最小単位 Datom
Datomic は事実を RDB のレコードや Mongodb のドキュメントのような形で保持していません。
代わりにDatomという事実のAtomicな最小単位に分解して保持しています。
Datomはエンティティ、属性、値、時刻から構成されています。
こうすることによりどんなDatomのセットも決まったデータ構造に埋め込むことなくクエリーから発見できていいそうです。
よく理解できてませんが、RDBやMongodbだとレコード(ドキュメント)の中身はどんなクエリーでも毎回同じ組み合わせだけど、それがクエリー次第で色んな組み合わせになるってことかな。
Amazon DynamoDBがバックエンド
DynamoDBがバックエンドとして使われていますが、そこは大して重要ではありません。
「DatomicがDynamoDBに付けた価値は伝統的なデータベースのファイルシステムに対するそれ」
DynamoDBはただのブロックデバイス的に使われているだけなのです。
また「DynamoDB以外の選択肢はまだない」との事なので今後他のストレージもサポートされるかもしれません。
2014/1/20追記
いろいろバックエンドとして使用できるストレージが増えました。下記の価格をご参照ください。
現段階ではJVMのみ
今のところ利用出来る言語はJVM系に限られています。 今後、他の言語もサポートする予定とのことです。
2014/1/20追記
JVM以外の言語からは一つのPeerを経由してREST APIでアクセスできます。
価格
2014/1/20更新
無料のFree Editionと有料のPro Editionがあります。 Free EditionはPeerが2つまでTransactorに接続でき、バックエンドとして使用できるストレージがPeerのメモリーとTransactorのローカルディスクです。メモリーは主に開発時やテストの時に便利です。 Pro Editionは料金に応じて接続できるPeerの数が増え、バックエンドとして使用できるストレージがDynamoDB、PostgreSQL等のRDB、Riak、Couchbase、Cassandra、Infinispan memory clusterです。
感想
Hacker Newsでもかなりの人が一体なんなんだこれはと戸惑ってる感じでした。
The Joy of Clojure の著者 fogus さんは「Datomicはエイリアンの高度なテクノロジーで満たされたUFOだ」と言っていましたが、全く同じように感じました。
Richが作らなければ、何年待ってもこんなのできなかったんじゃないかと思います。
私は気に入ったなんてレベルじゃないので、これからどんどん使っていきたいです。
whitepaper(pdf)が詳細を分かりやすくまとめているので興味がある方は一読をおすすめします。
Datomic がエレガントだと感じた方はきっとClojureにも感銘を受けるでしょう!ぜひ試してみてください。 Clojure のエレガントなところ
blog comments powered by Disqus